What the heck is a Chu space? And whatever it is, does it really belong with all the rich mathematical structures we know and love?

Say you have some stuff. What can you do with it?
Maybe it’s made of little pieces, and you can do a different thing with each little piece.
But maybe the pieces are structured in a certain way, and you aren’t allowed to do anything that would break this structure.
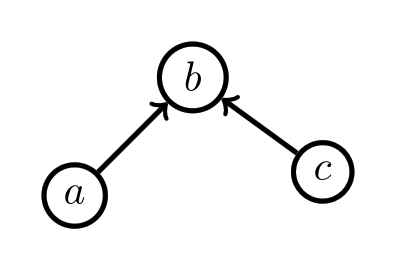
A Chu space is a versatile way of formalizing anything like that!
To represent something in a Chu space, we’ll put the names of our pieces on the left. How about the rules? For a Chu space, the rules are about allowed ways to color our pieces. To represent these rules, we can simply make columns showing all the allowed ways we can color our pieces (just get rid of any columns that break the rules). Here’s what a basic 3-element set (pictured on the left) looks like as a Chu space:
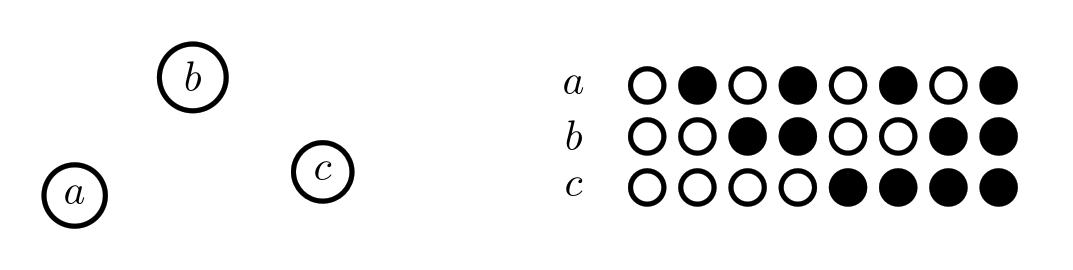
It doesn’t have any sort of structure, so we show that by allowing all the possible colorings (with two colors). Chu spaces that don’t have any rules (i.e. all colorings are allowed) are equivalent to sets.
What about the one with the arrows from above? How can we make an arrow into a coloring rule? One way we could do it is by stipulating that if there’s an arrow  , we’ll make a rule that if
, we’ll make a rule that if  is colored black, then
is colored black, then  has to be colored black too, where and can stand in for any of the pieces. Here’s what that Chu space looks like:
has to be colored black too, where and can stand in for any of the pieces. Here’s what that Chu space looks like:

Spend a minute looking at the picture until you’re convinced that our coloring rule is obeyed for every arrow on the left side of the picture. Any Chu space that has this kind of arrow rule has the structure of a poset.
There and back again
If we have two Chu spaces, say  and
and  , what sort of maps should we be able to make between them?
, what sort of maps should we be able to make between them?
We’d like to be able to map the pieces of to the pieces of . So this part of our map will just be a normal function between sets:
![\[f:A_{\textsf{pieces}}\rightarrow B_{\textsf{pieces}}\]](http://adelelopez.com/wp-content/ql-cache/quicklatex.com-59d32aa4aabd759d258100b99c449f8a_l3.png "Rendered by QuickLaTeX.com")
But we also want our maps to respect the rules of as it maps to . How can we check this?
Let’s think through how we would be able to tell if a potential map did break the rules. The map will take pieces of to pieces of , so let’s look at the pieces of that got mapped onto, i.e.  . It will help if we have a concrete example in mind, so let’s consider a potential map that we think should break the rules: one that breaks the arrow structure of a poset by breaking it up into a mere set. For simplicity, we’ll just have the pieces map
. It will help if we have a concrete example in mind, so let’s consider a potential map that we think should break the rules: one that breaks the arrow structure of a poset by breaking it up into a mere set. For simplicity, we’ll just have the pieces map  take pieces to pieces with the same label.
take pieces to pieces with the same label.
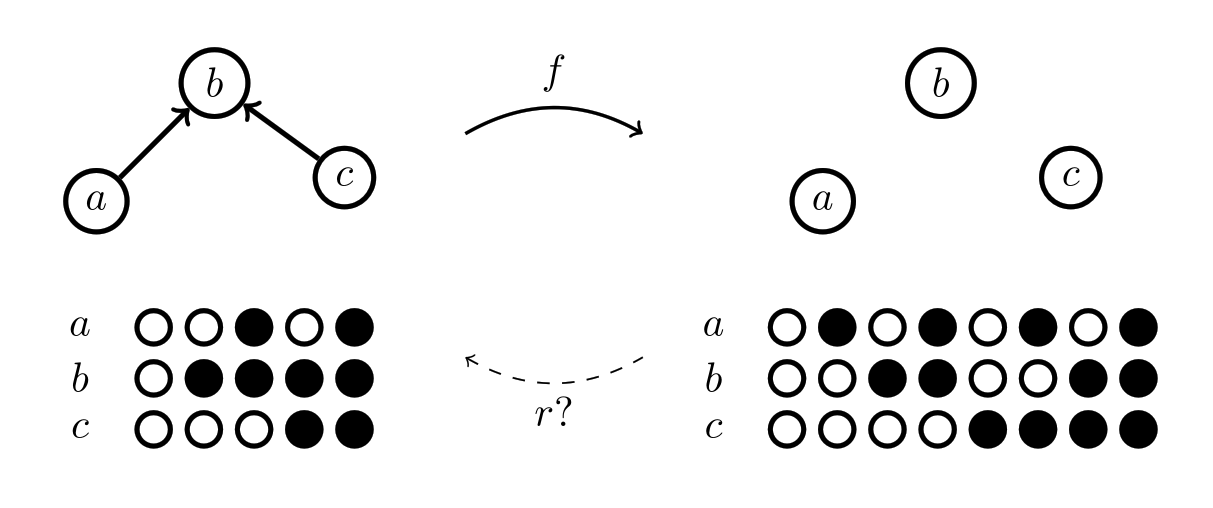
We can see now that if this potential map breaks the rules, it must be because some of the colorings for are invalid. Specifically, the colorings highlighted in red:
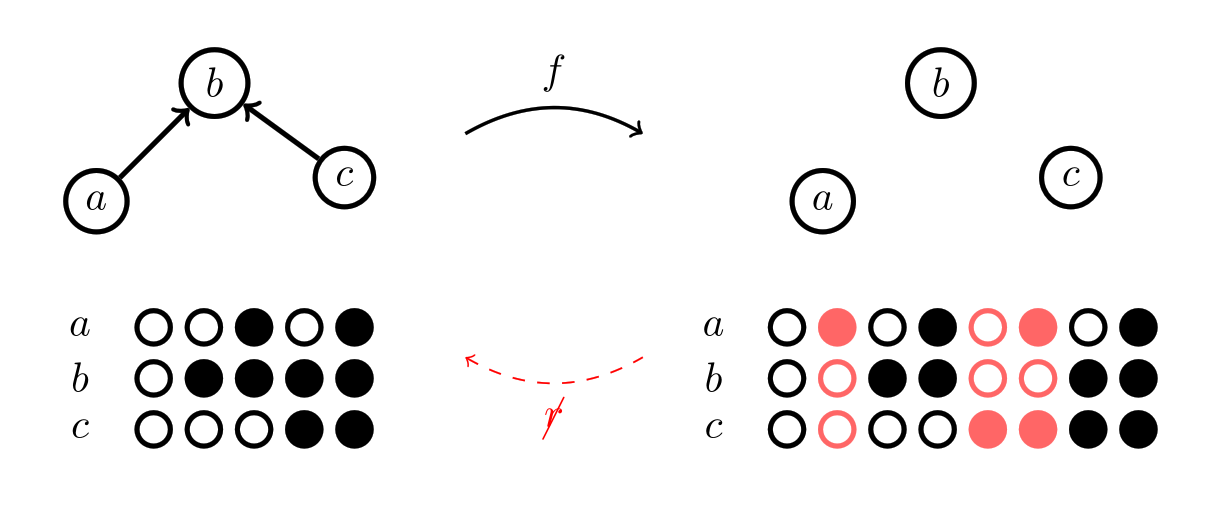
The problem with these colorings is that there are no colorings in the original space for them to correspond to; so they must break one of the rules of the original space. So for a map that does follow the rules, we’ll want to make sure every coloring in has a corresponding coloring in . This will be another function between sets, this time going backwards between the sets of colorings:
![\[r:B_{\textsf{colorings}}\rightarrow A_{\textsf{colorings}}\]](http://adelelopez.com/wp-content/ql-cache/quicklatex.com-6a49f285c7cdd5b09c1f374e00865148_l3.png "Rendered by QuickLaTeX.com")
Now let’s look at an example of what we expect should be a legit map between Chu spaces.
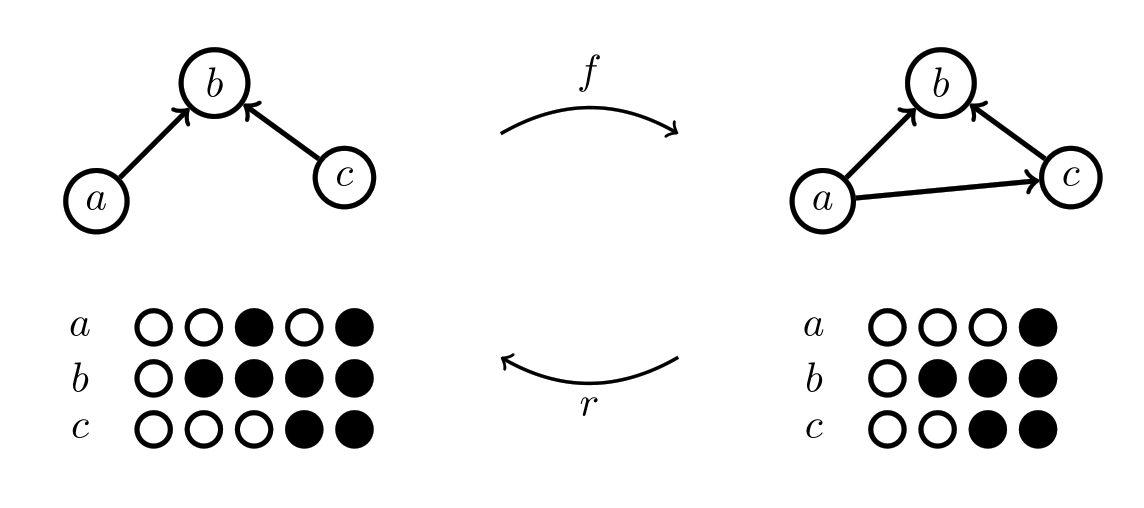
Again, we are just mapping pieces to pieces with the same labels. This map is ok because even though has some additional structure, it respects all of the structure from .
The last part we need to define a map between Chu spaces is to determine exactly what it means for colorings of to have a corresponding coloring in . For a given piece , and a given coloring  , we have a function that gives us the color of using the coloring :
, we have a function that gives us the color of using the coloring :
![\[\mathsf{Color}_A:A_{\mathsf{Pieces}}\times A_{\mathsf{Colorings}} \rightarrow \mathsf{Palette}\]](http://adelelopez.com/wp-content/ql-cache/quicklatex.com-b7deee7b74263c971a4eb88c53b4758e_l3.png "Rendered by QuickLaTeX.com")
We want to make sure that if we have a coloring from , that it gets taken back to a compatible coloring in . The coloring it gets taken back to is  , and we can check it’s color on any piece
, and we can check it’s color on any piece  from with
from with  .
.
What do we want this to be the same as? It should be the same as the our coloring from on all the pieces that maps onto! We can check these colors with  . And so, we can finish our notion of a Chu map by making sure that for all the pieces of , and for all colorings of , that the following equation holds:
. And so, we can finish our notion of a Chu map by making sure that for all the pieces of , and for all colorings of , that the following equation holds:
![\[\mathsf{Color}_B(f(p), s)=\mathsf{Color}_A(p, r(s))\]](http://adelelopez.com/wp-content/ql-cache/quicklatex.com-1b95b5d7b40a4ed54c409dd0831a565c_l3.png "Rendered by QuickLaTeX.com")
Thus, a map between Chu spaces is made of any two functions and  which satisfy the above equation.
which satisfy the above equation.
Basic concepts
In order to talk about Chu spaces more easily, let’s define some terminology.
The set of “pieces” is known as the carrier, and each “piece” is called a point. These points index the rows. Likewise, each “coloring” (i.e. column) is indexed by a state, and the set of states is called the cocarrier. Each point-state pair has a “color” which is a value taken from the alphabet (or “palette”). For a Chu space  with point and state , we’ll denote this value by
with point and state , we’ll denote this value by  .
.
A Chu transform is a map between two Chu spaces:  . It is composed of two functions, the forward function from the carrier of to the carrier of , and the reverse function r from the cocarrier to the cocarrier of . These must satisfy the Chu condition in order for this
. It is composed of two functions, the forward function from the carrier of to the carrier of , and the reverse function r from the cocarrier to the cocarrier of . These must satisfy the Chu condition in order for this  to be a Chu transform: For every point
to be a Chu transform: For every point  of and every state
of and every state  of ,
of ,
![\[B\langle f(p_A), s_B\rangle = A\langle p_A, r(s_B)\rangle\]](http://adelelopez.com/wp-content/ql-cache/quicklatex.com-5771f019df5d2a26580b55f27f041019_l3.png "Rendered by QuickLaTeX.com")
We say a Chu space is separable if all the rows are unique. It’s extensional if all the columns are unique, and biextensional if both the rows and the columns are unique. We can make any Chu space biextensional simply by striking out any duplicate rows and columns. This is known as the biextensional collapse. Any two Chu spaces with the same biextensional collapse are biextensionally equivalent. It’s very common in applications to only consider things up to biextensional equivalence.
Chu spaces with Chu transforms form a category. This category is typically called  , where
, where  is the alphabet.
is the alphabet.
Representation
Lots of categories are fully embedded into  , and even more if we allow arbitrarily many colors. Let’s look at some examples so we can get a better feel for how we can represent different kinds of rules with coloring rules.
, and even more if we allow arbitrarily many colors. Let’s look at some examples so we can get a better feel for how we can represent different kinds of rules with coloring rules.
For a topological space, the pieces will be all the points. The allowed colorings will be exactly the ones where the pieces colored white make up an open set, and the pieces colored black make up a closed set. It’s then easy to how the Chu transform gives us exactly continuous functions between topological spaces!
This example also motivates why Chu spaces are called spaces: for any two color Chu space, we can think of each column representing a generalized open set, containing the white colored points.
If we use more colors, we can embed any category of algebraic objects fully and faithfully into Chu! In other words, Chu can represent any algebraic category. To see how this works, let’s see how we can represent any group. The points will be the elements of the group. We’ll need 8 colors, which we’ll think of as being the 8 combinations of red, green, and blue. We’ll think of each relation  as having the slot colored red, the
as having the slot colored red, the  spot colored green, and the
spot colored green, and the  spot colored blue. Only colorings which have at least one element in the right color slot for ALL the relations of the group are allowed. We need 8 colors to represent the possibility of the same element appearing in multiple slots. For example, with the zero group, 0 appears in every slot for every relation, so the 0 row will have all the colors which have at least red, green, or blue “turned on”:
spot colored blue. Only colorings which have at least one element in the right color slot for ALL the relations of the group are allowed. We need 8 colors to represent the possibility of the same element appearing in multiple slots. For example, with the zero group, 0 appears in every slot for every relation, so the 0 row will have all the colors which have at least red, green, or blue “turned on”:
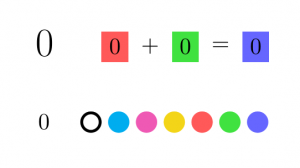
This is not an economical representation. Even for just the cyclic group of order 2, we need lots of rules (41, to be exact)¹.
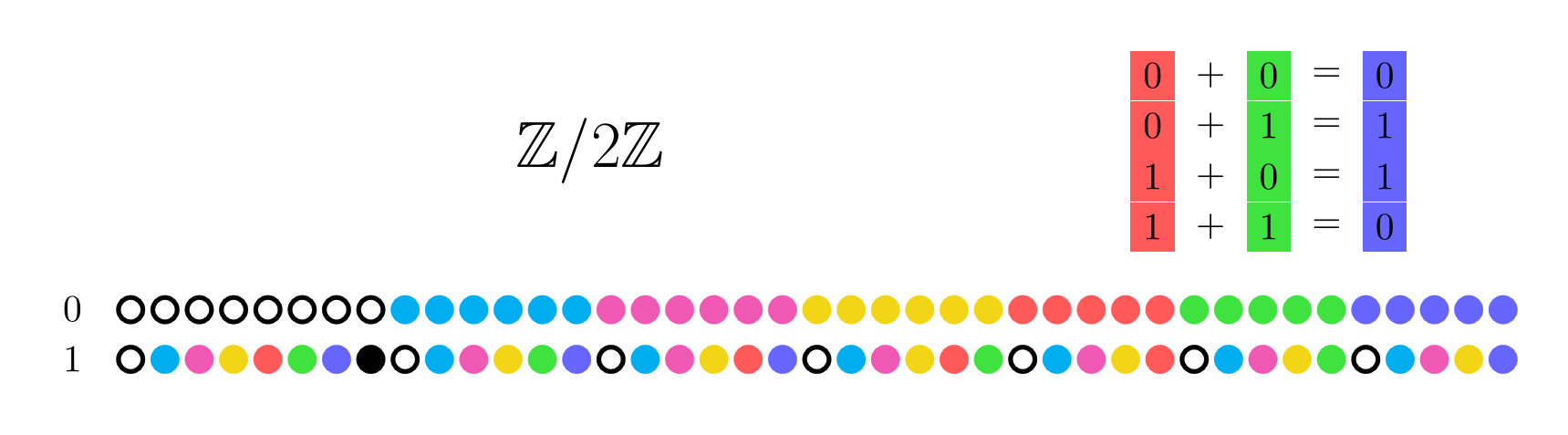
The Klein 4-group requires 1045 columns under this representation! So the following pictures will be truncated, so that we can see the essential idea without being overwhelmed. Let’s consider a potential Chu transform between  and
and  with this representation:
with this representation:
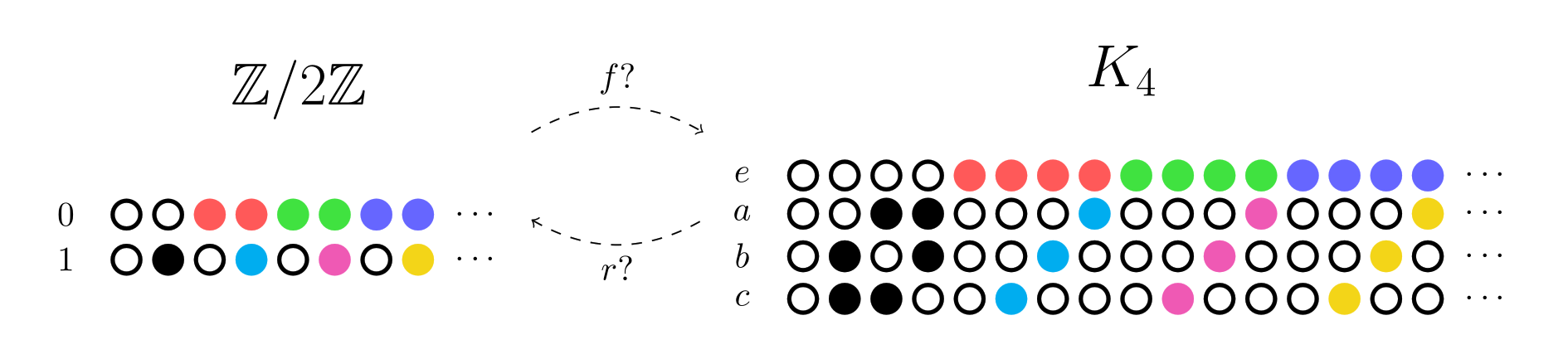
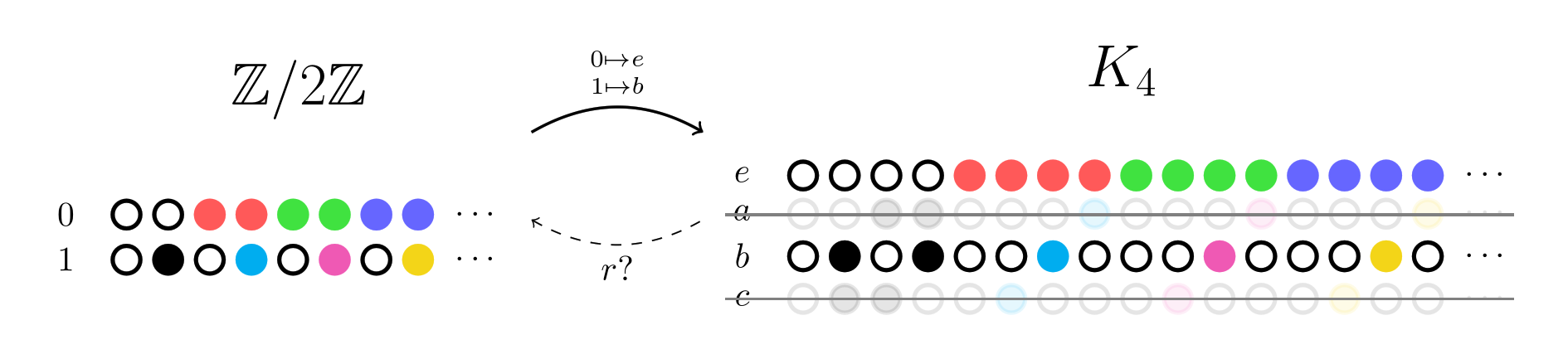
The forward map is almost like a question. It chooses which rows 0 and 1 should correspond to (say  and respectively), and asks if this is an allowed transformation.
and respectively), and asks if this is an allowed transformation.
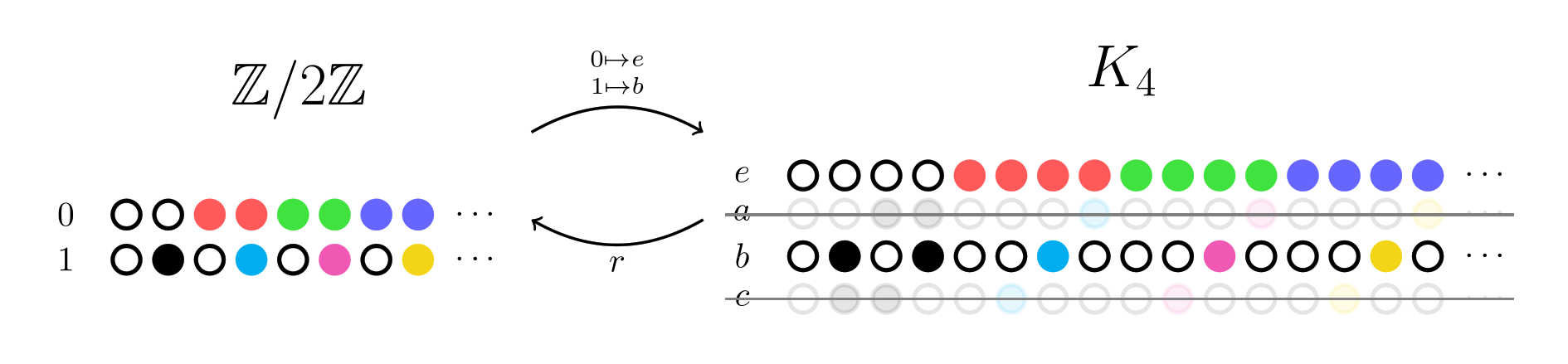
The reverse map responds by finding the representative of each column from . E.g. the 2nd column of must be mapped to the 2nd column of . If it can’t find such a map, we can think of this as an answer in the negative.
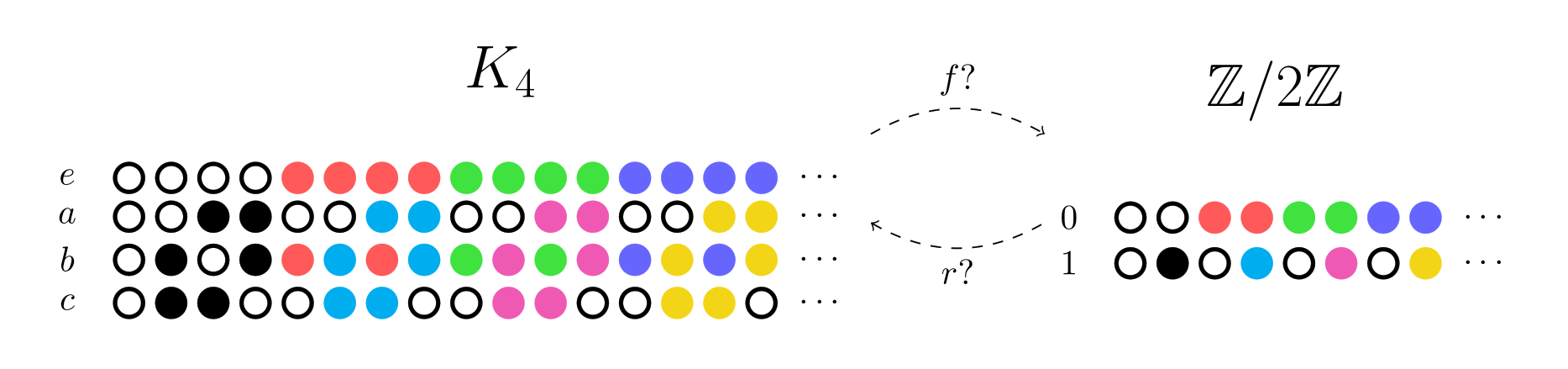
Let’s look at another example where the reverse map is slightly more interesting. We expect there to be a group homomorphism from to  , so let’s check that this is the case for the Chu spaces as well. (We’ll show a different subset of the columns of in this example.)
, so let’s check that this is the case for the Chu spaces as well. (We’ll show a different subset of the columns of in this example.)
Again, we’ll choose a forward map, this time taking and to 0, and  and
and  to 1. The reverse map then verifies that the group structure is satisfied, by looking for a column of for every column of .
to 1. The reverse map then verifies that the group structure is satisfied, by looking for a column of for every column of .
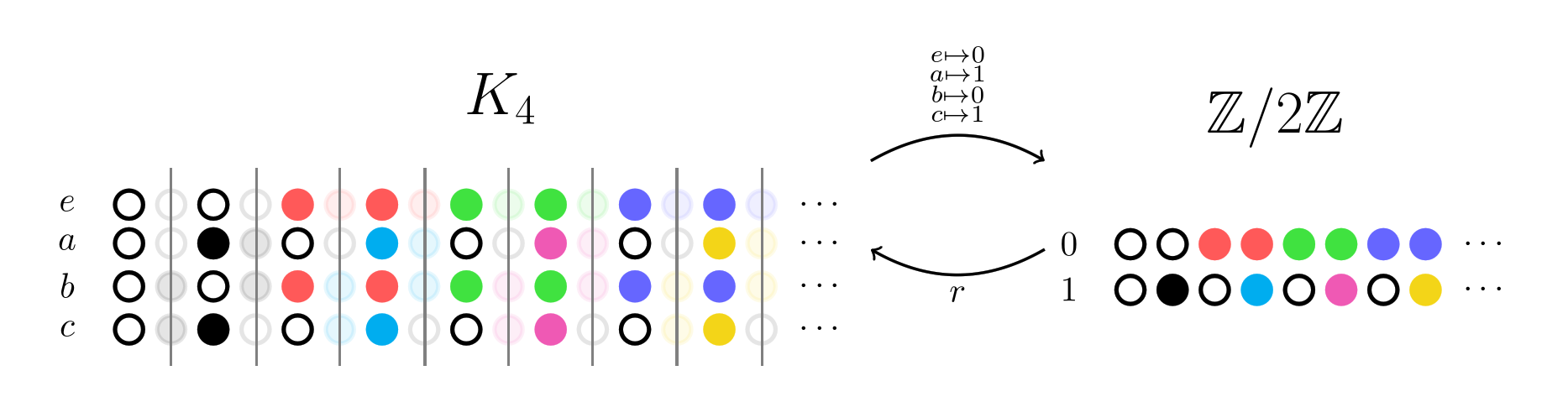
Notice how the alternating color columns get chosen by . This is mandated by the Chu condition, given that maps its rows in an alternating pattern.
Notice also how we didn’t need to add anything else to properly represent group axioms, such as the fact that every group has an identity. Instead, this is encoded implicitly: the identity row will be the only row that doesn’t contain any black, so the Chu condition thus ensures it must always be mapped to the identity of another group represented this way. By simply specifying all the relations that are allowed, we’ve implicitly specified the entire structure! This seemingly innocuous observation is at the heart of the celebrated Yoneda lemma.
Yoneda
The Yoneda lemma could rightly be called “the fundamental theorem of category theory”. While fundamentally a simple result, it is notoriously difficult to understand. An important corollary is the Yoneda embedding (and also the co-Yoneda embedding). There is an analog of the Yoneda embedding for Chu spaces which can be proved directly (without the Yoneda lemma) and which is conceptually simpler! I’ll prove that version in full here, since I found it enlightening to see exactly how it works.
Theorem: Every small² category embeds fully into  .
.
Proof: The embedding works by defining a functor  . For each object
. For each object  ,
,  takes this object to the Chu space where the points are all the arrows into , and the states are all the arrows out of . Here’s an example category
takes this object to the Chu space where the points are all the arrows into , and the states are all the arrows out of . Here’s an example category  :
:
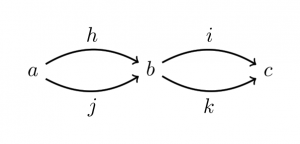
And here are the three Chu spaces that makes out of (one for each object), along with some of the induced Chu transforms (which will be defined below):
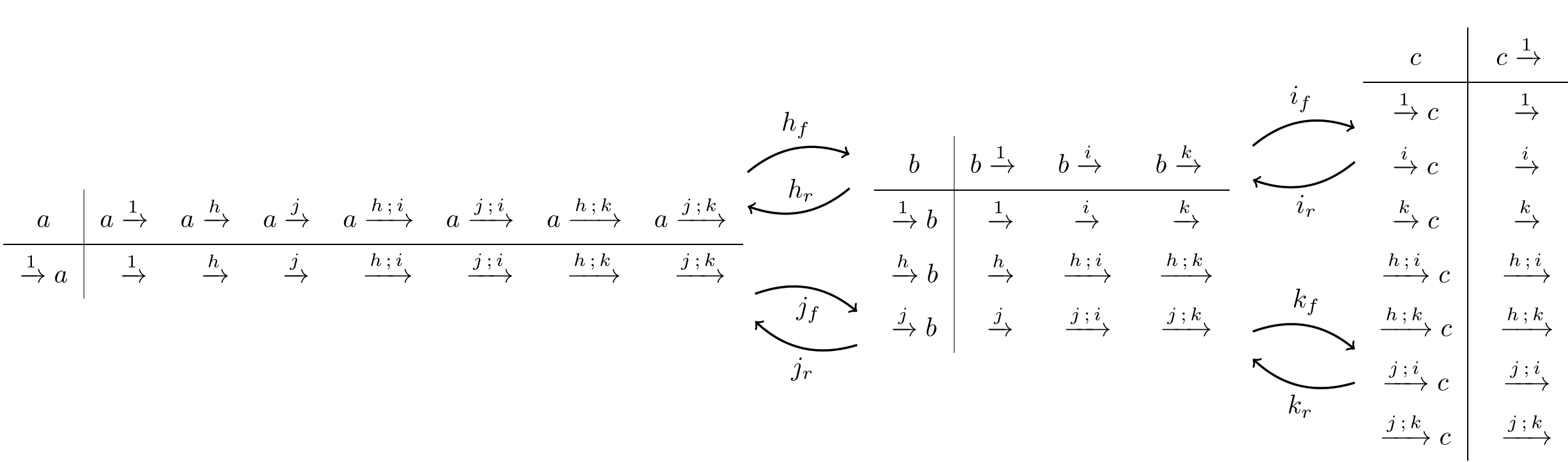
In any case,  is separable because the identity column will be different for each distinct point (i.e. incoming morphism). Similarly, it is extensional since the identity row will be different for each distinct state (i.e. outgoing morphism). So
is separable because the identity column will be different for each distinct point (i.e. incoming morphism). Similarly, it is extensional since the identity row will be different for each distinct state (i.e. outgoing morphism). So  is biextensional.
is biextensional.
Now consider a morphism  in .
in .  must of course be a Chu transform, hence is composed of a pair of functions
must of course be a Chu transform, hence is composed of a pair of functions  between the carriers and cocarriers of and
between the carriers and cocarriers of and  . Specifically,
. Specifically,  will take a point of (i.e. incoming morphism to ) to a point of (an incoming morphism to
will take a point of (i.e. incoming morphism to ) to a point of (an incoming morphism to  ) defined by
) defined by  . Similarly,
. Similarly,  will take a state of to a state of via
will take a state of to a state of via  . This satisfies the Chu condition since function composition is associative:
. This satisfies the Chu condition since function composition is associative:
![\[Y(d)\langle g_f(p), s \rangle = g_f(p) \,; s = (p \,; g) \,; s = p \,; (g \,; s) = p \,; g_r(s) = Y(c)\langle p, g_r(s) \rangle\]](http://adelelopez.com/wp-content/ql-cache/quicklatex.com-1aceaf8c2f151e3f1f26bdbc7acc113d_l3.png "Rendered by QuickLaTeX.com")
This functor is faithful, which means that it keeps morphisms distinct: if  are distinct morphisms, then and
are distinct morphisms, then and  are also distinct. We can see this by checking the values of
are also distinct. We can see this by checking the values of  and
and  .
.
And finally, this functor is full, which means that every Chu transform between the Chu spaces of comes from a morphism of . We can see this by taking an arbitrary Chu transform  . From the Chu condition
. From the Chu condition  , which implies that
, which implies that  . By construction, this is a morphism
. By construction, this is a morphism  of starting at and ending at , i.e
of starting at and ending at , i.e  . Again by the Chu condition,
. Again by the Chu condition,  . Similarly,
. Similarly,  . Thus, is exactly
. Thus, is exactly  , and is exactly
, and is exactly  as given by
as given by  . This means our transform was just . QED
. This means our transform was just . QED
Having a full and faithful embedding into means that our category is represented by . This is quite similar to how groups can be represented by vector spaces!
Also notice how we needed three things to make this work: identity morphisms for each object, composition of morphisms, and associativity of composition. These are exactly the requirements for a category! I think this explains why categories are such a fruitful abstraction: it has exactly what we need to make the Yoneda embedding work, and no more.
Final thoughts
Hopefully I’ve convinced you that Chu spaces are indeed a mathematical abstraction worth knowing. I appreciate in particular how they provide such a concrete way of understanding otherwise slippery things.
This post just scratches the surface of what you can do with Chu spaces. Now that I’ve laid out the basics, I plan to continue with another post about how Chu spaces relate to linear logic, cartesian frames, Fourier transforms, and more!
Most of the stuff in this post can be found in Pratt’s Coimbra paper. There aren’t many distinct introductions to Chu spaces so I thought it was worth retreading this ground from a somewhat different perspective.
Special thanks to Evan Hubinger for encouraging me to write this up, and to Nisan Stiennon for his helpful feedback!
Footnotes
[1]: For , there are four relations of the form  . Let’s start with 0 + 0 = 0. To cover this relation, we must turn on either the red, green, or blue light for 0. So the 0 row will never be colored black. If we color 0 white, then we’ve covered every relation, since every relation has 0 in either the r, g, or b slot. On the other hand, if we colored 0 green, then we would need to turn on either the blue or the green light for 1 in order to cover the second equation 0 + 1 = 1. If we turned on the blue light for 1, then the third equation 1 + 0 = 1 would be covered already, but the fourth equation 1 + 1 = 0 won’t. We’ll have to turn on either the red or the green light for 1 in order to cover the fourth equation. Here’s the code I used to calculate these.
. Let’s start with 0 + 0 = 0. To cover this relation, we must turn on either the red, green, or blue light for 0. So the 0 row will never be colored black. If we color 0 white, then we’ve covered every relation, since every relation has 0 in either the r, g, or b slot. On the other hand, if we colored 0 green, then we would need to turn on either the blue or the green light for 1 in order to cover the second equation 0 + 1 = 1. If we turned on the blue light for 1, then the third equation 1 + 0 = 1 would be covered already, but the fourth equation 1 + 1 = 0 won’t. We’ll have to turn on either the red or the green light for 1 in order to cover the fourth equation. Here’s the code I used to calculate these.
[2]: A small category is simply one where the objects and morphisms are both sets. They could even be uncountable sets! A category that isn’t small is  . That’s because the objects of this category are all sets, and we can’t have the set of all sets lest we run into Russell’s paradox.
. That’s because the objects of this category are all sets, and we can’t have the set of all sets lest we run into Russell’s paradox.
0 Comments